

اجرای مدلهای زبانی بزرگ (LLM) بهصورت آفلاین روی سیستم شخصی
آموزش کامل و کاربردی LM Studio
در چند سال اخیر، هوش مصنوعی مولد عملاً شیوه کار، تولید محتوا، برنامهنویسی و حتی تصمیمگیری ما را تغییر داده است. ابزارهایی مثل ChatGPT، Claude و Gemini استاندارد جدیدی برای تعامل با زبان طبیعی ساختهاند؛ اما یک مشکل اساسی دارند:
همهچیز به اینترنت و سرورهای ابری وابسته است.
اینجاست که یک سؤال مهم مطرح میشود:
آیا میشود هوش مصنوعی قدرتمند داشت، بدون اینترنت، بدون هزینه اشتراک، و بدون ارسال دادهها به بیرون؟
پاسخ کوتاه است: بله، با LM Studio.
LM Studio یکی از بهترین و سادهترین ابزارها برای اجرای مدلهای زبانی بزرگ (LLM) بهصورت آفلاین روی لپتاپ یا کامپیوتر شخصی است. در این راهنما، قدمبهقدم یاد میگیریم:
-
LM Studio دقیقاً چیست و چرا اهمیت دارد
-
چه سختافزاری برای اجرای مدلها نیاز داریم
-
چطور بهترین مدل GGUF را انتخاب کنیم
-
چطور LM Studio را به API، VS Code و پروژههای واقعی وصل کنیم
اگر به هوش مصنوعی محلی (Local AI)، حریم خصوصی یا کاهش هزینهها اهمیت میدهی، این مقاله دقیقاً برای تو نوشته شده.
LM Studio چیست و چرا اینقدر مهم شده؟

LM Studio یک نرمافزار دسکتاپ (برای ویندوز، مک و لینوکس) است که به شما اجازه میدهد مدلهای زبانی متنباز مثل Llama، Mistral، Qwen، DeepSeek و… را مستقیماً روی سیستم خودتان اجرا کنید.
از نظر فنی، LM Studio:
-
بر پایه کتابخانهی قدرتمند llama.cpp ساخته شده
-
از فرمت استاندارد GGUF استفاده میکند
-
یک رابط گرافیکی (GUI) تمیز و حرفهای دارد
-
پیچیدگی اجرای LLMها را برای کاربر حذف میکند
به زبان ساده:
LM Studio مثل یک «پل» است بین سختافزار شما و مدلهای پیچیده هوش مصنوعی.
بدون نیاز به:
-
ترمینال
-
تنظیمات پیچیده CUDA
-
یا درگیری با فایلهای عجیبوغریب
چرا اجرای هوش مصنوعی بهصورت آفلاین مهم است؟
تا وقتی فقط برای سرگرمی یا کارهای عمومی از ChatGPT استفاده میکنی، شاید مشکلی حس نکنی.
اما برای استفاده حرفهای، چالشها خیلی جدیتر میشوند.
۱. حریم خصوصی و امنیت دادهها
در مدلهای ابری:
-
تمام پرامپتها
-
فایلها
-
کدها
به سرورهای خارجی ارسال میشوند.
برای حوزههایی مثل:
-
حقوق و وکالت
-
پزشکی
-
تحقیق و توسعه
-
کسبوکارها و استارتاپها
این موضوع ریسک بزرگ امنیتی محسوب میشود.
در LM Studio:
✅ همهچیز روی سیستم خودت اجرا میشود
✅ هیچ دادهای از دستگاه خارج نمیشود
✅ حتی بدون اینترنت هم کار میکند
۲. حذف هزینههای اشتراک و توکن

مدلهای ابری معمولاً:
-
اشتراک ماهانه دارند
-
یا هزینه بر اساس مصرف توکن میگیرند
اما در LM Studio:
-
استفاده کاملاً رایگان است
-
هیچ محدودیت تعداد پیام یا طول متن نداری
تنها هزینهای که میکنی:
-
سختافزار
-
و برق مصرفی سیستم است
برای استفاده طولانیمدت، این تفاوت خیلی بزرگ است.
۳. دسترسی همیشگی، حتی بدون اینترنت
تحریمها، قطعی اینترنت یا محدودیتهای منطقهای میتوانند دسترسی به مدلهای ابری را قطع کنند.
LM Studio:
-
کاملاً آفلاین اجرا میشود
-
روی هر سیستم شخصی قابل استفاده است
-
وابسته به هیچ سرویس خارجی نیست
۴. کنترل کامل روی مدل و نسخه
در سرویسهای ابری:
-
مدلها دائماً آپدیت میشوند
-
رفتارشان تغییر میکند
-
بعضی قابلیتها حذف یا محدود میشود
در اجرای محلی:
-
دقیقاً همان مدلی را اجرا میکنی که انتخاب کردهای
-
نسخه، کوانتیزاسیون و تنظیمات کاملاً دست خودت است
این موضوع برای کارهای تخصصی یا پروژههای بلندمدت حیاتی است.
مقایسه LM Studio با ابزارهای مشابه

در دنیای Local AI فقط LM Studio نیست. ابزارهای معروف دیگری هم وجود دارند، اما تفاوتها مهماند.
|
ویژگی |
LM Studio |
Ollama |
GPT4All |
|---|---|---|---|
|
رابط کاربری |
گرافیکی حرفهای |
خط فرمان (CLI) |
گرافیکی ساده |
|
دانلود مدل |
جستجو مستقیم در Hugging Face |
کتابخانه اختصاصی |
محدود |
|
API محلی |
سازگار با OpenAI |
دارد |
محدود |
|
کنترل GPU |
دقیق و دستی |
بیشتر خودکار |
پایه |
|
مناسب برای |
کاربران حرفهای و دسکتاپ |
توسعهدهندگان و سرور |
مبتدیها |
جمعبندی ساده:
-
اگر توسعهدهنده CLI هستی → Ollama
-
اگر خیلی مبتدی هستی → GPT4All
-
اگر بهترین تعادل قدرت + کنترل + تجربه کاربری را میخواهی → LM Studio
قبل از نصب LM Studio، این را باید بدانی (سختافزار)
اجرای مدلهای زبانی بزرگ، شوخی نیست 😄
این یکی از سنگینترین کارهایی است که یک سیستم شخصی میتواند انجام دهد.
مهمترین محدودیتها:
-
VRAM کارت گرافیک
-
RAM سیستم
-
پهنای باند حافظه
پارامتر مدل یعنی چه؟
وقتی میبینی نوشته:
-
7B
-
13B
-
30B
یعنی مدل چند میلیارد پارامتر دارد.
هرچه عدد بزرگتر → مدل باهوشتر، اما سنگینتر.
نقش کوانتیزاسیون (Quantization)
بهجای اجرای مدل با دقت کامل، وزنها فشرده میشوند:
-
8 بیت (Q8) → دقت بالا، حجم زیاد
-
4 بیت (Q4) → تعادل عالی
-
2 بیت (Q2) → سبک ولی افت کیفیت
🔑 استاندارد طلایی برای اکثر کاربران: Q4_K_M
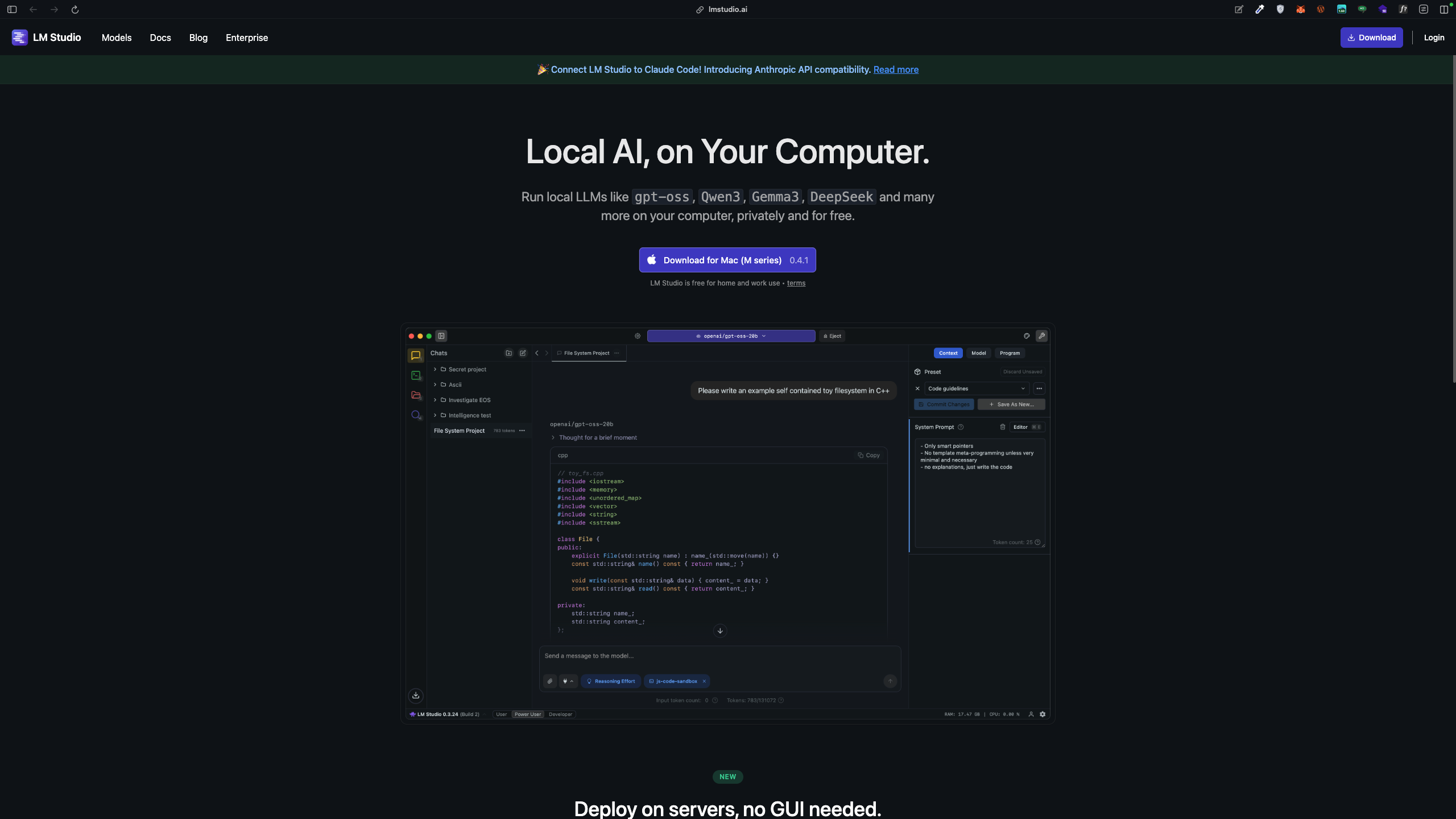
جهت دانلود lm studio کلیک کنید
تخمین سختافزار موردنیاز (Q4)
مک یا ویندوز؟ کدام برای اجرای LM Studio بهتر است؟
یکی از سؤالهای پرتکرار این است:
LM Studio روی مک بهتر جواب میدهد یا ویندوز؟
جواب کوتاه و صادقانه:
👉 اگر مکهای جدید اپل (سری M) را داری، اوضاع خیلی به نفع توست.
👉 اگر ویندوزی هستی، کارت گرافیک NVIDIA برگ برنده توست.
حالا دقیقتر بررسی کنیم.
اجرای LM Studio روی مکهای سری M (M1 تا M4)
اپل با معرفی معماری Unified Memory ورق بازی را عوض کرد.
در این معماری:
-
CPU
-
GPU
-
Neural Engine
همه از یک حافظه مشترک استفاده میکنند.
این یعنی چی؟
یعنی اگر مکبوک تو ۳۲ یا ۶۴ گیگ رم دارد، GPU هم میتواند به همان مقدار حافظه دسترسی داشته باشد.
📌 مثال واقعی:
یک مکبوک با ۶۴GB رم میتواند:
-
مدلهای ۳۰B
-
حتی بعضی ۴۰Bها
را بدون نیاز به کارت گرافیک جداگانه اجرا کند.
LM Studio روی مک:
-
از Metal و MLX استفاده میکند
-
بهینهسازی شده برای Apple Silicon
-
مصرف انرژی کمتر و پایداری بالا دارد
🔹 اگر تولیدکننده محتوا، محقق یا توسعهدهندهای که زیاد جابهجا میشود هستی → مک انتخاب عالی است.
اجرای LM Studio روی ویندوز و لینوکس
در دنیای ویندوز و لینوکس، داستان فرق میکند.
اینجا VRAM کارت گرافیک حرف اول را میزند.
بهترین انتخاب:
-
کارتهای NVIDIA
-
بهخاطر CUDA و پشتیبانی نرمافزاری قوی
LM Studio از:
-
NVIDIA (عالی)
-
AMD (قابل قبول)
-
Intel iGPU (محدود)
پشتیبانی میکند، اما:
-
بیشترین سرعت و پایداری → NVIDIA
-
مخصوصاً سری RTX 30 و 40
📌 اگر سیستم دسکتاپ داری و قصد اجرای مدلهای سنگین را داری، ویندوز + RTX هنوز انتخاب شماره یک است.
آموزش نصب LM Studio (گامبهگام)
نصب LM Studio سخت نیست، ولی رعایت چند نکته کوچک میتواند کلی دردسر را کم کند.
نصب LM Studio در ویندوز (Windows)
۱. وارد سایت رسمی LM Studio شو
۲. نسخه Windows (.exe) را دانلود کن
۳. فایل را اجرا کن (نصب کلاسیک Next-Next-Finish)
بعد از نصب، حتماً این موارد را چک کن:
✅ درایور کارت گرافیک NVIDIA:
-
آخرین نسخه Game Ready یا Studio Driver
-
بدون درایور درست، GPU اصلاً شناسایی نمیشود
✅ تنظیم مهم ویندوز:
-
Settings → System → Display → Graphics
-
گزینه Hardware-accelerated GPU scheduling را فعال کن
این کار تأخیر (Latency) را کمتر میکند.

نصب LM Studio در مک (macOS)
اینجا خیلی مهم است که نسخه درست را دانلود کنی.
🔹 اگر مکات M1، M2، M3 یا M4 است:
-
حتماً نسخه Apple Silicon را بگیر
این نسخه:
-
از MLX استفاده میکند
-
تا ۳۰٪ سریعتر از روشهای قدیمی است
🔹 مکهای Intel:
-
پشتیبانی رسمی ضعیفتر شده
-
اگر هنوز Intel هستی، انتظار عملکرد بالا نداشته باش
بعد از دانلود:
-
فایل DMG را باز کن
-
LM Studio را به Applications بکش
-
تمام
نصب LM Studio در لینوکس (Linux)
برای لینوکسبازها 😄
LM Studio بهصورت AppImage ارائه میشود.
مراحل:
chmod +x LM_Studio-x64.AppImage
./LM_Studio-x64.AppImage
پیشنهاد:
-
Ubuntu 20.04 یا بالاتر
-
برای NVIDIA: نصب درایور اختصاصی + CUDA
اگر GPU شناسایی نشود، تقریباً کل قدرت سیستم هدر میرود.
بعد از نصب: مهمترین قدم → دانلود مدل GGUF
LM Studio بدون مدل هیچ کاری نمیکند.
مدلها مغز ماجرا هستند.
برای این کار:
-
وارد تب Discover شو
-
مستقیماً به Hugging Face وصل هستی
-
بدون نیاز به مرورگر یا دانلود دستی
GGUF چیست و چرا همهچیز حول آن میچرخد؟
GGUF یک فرمت استاندارد برای مدلهای LLM است که توسط تیم llama.cpp طراحی شده.
مزیتهای GGUF:
-
تکفایلی (همهچیز داخل یک فایل)
-
لود سریعتر
-
سازگار با CPU و GPU
-
مدیریت ساده در LM Studio
برخلاف فرمتهای قدیمی، نیازی نیست:
-
توکنایزر جداگانه
-
فایل کانفیگ
-
یا پوشههای متعدد
همهچیز داخل همان یک فایل است.
انتخاب نسخه درست مدل: Q4 یا Q8؟
وقتی یک مدل را جستجو میکنی، با اسمهای عجیب روبهرو میشوی:
-
Q8_0
-
Q4_K_M
-
Q3_K_S
-
Q2_K
بیایم ساده کنیم 👇
Q8 (۸ بیت)
-
نزدیکترین حالت به مدل اصلی
-
حجم زیاد
-
مصرف VRAM بالا
-
مناسب کارهای خیلی حساس (ریاضی، علمی)
Q4_K_M (۴ بیت – انتخاب طلایی ⭐)
-
بهترین تعادل بین کیفیت و سرعت
-
نصف حجم Q8
-
افت کیفیت بسیار ناچیز
۹۰٪ کاربران حرفهای همین را استفاده میکنند.
Q2 (۲ بیت)
-
خیلی سبک
-
افت محسوس کیفیت
-
فقط برای تست یا سیستمهای ضعیف
🔑 قانون ساده:
اگر شک داری، Q4_K_M را انتخاب کن
چند مدل پیشنهادی برای شروع
اگر تازه وارد دنیای LM Studio شدی، اینها انتخابهای امن هستند:
-
Llama 3.1 8B Q4_K_M → همهفنحریف
-
Mistral 7B Q4 → سریع و خوشفهم
-
Qwen 2.5 7B → عالی برای فارسی و کدنویسی
-
DeepSeek Coder → مخصوص برنامهنویسی
تنظیمات حرفهای LM Studio برای حداکثر سرعت و کیفیت
اینجا جاییه که خیلیها LM Studio رو نصب میکنن… ولی از نصف توانش هم استفاده نمیکنن.
در حالی که با چند تنظیم درست، میتونی ۲ تا ۵ برابر سرعت بهتر بگیری.
در LM Studio، وقتی یک مدل رو لود میکنی، در سمت راست صفحه یک پنل تنظیمات میبینی که مربوط به Inference (اجرای مدل) است. این بخش، قلب ماجراست.
Context Length (طول کانتکست) یعنی چی؟
Context Length مشخص میکند مدل:
-
چه مقدار از مکالمههای قبلی
-
یا چه حجمی از فایلها و متنها
را همزمان درک میکند.
مقادیر رایج:
-
2048 → پیشفرض و سبک
-
4096 → مناسب بیشتر کارها
-
8192 → تحلیل مقاله و کد
-
32768+ → اسناد حجیم، RAG
اما یک نکته خیلی مهم 👇
افزایش Context Length رایگان نیست.
هرچه کانتکست بیشتر:
-
مصرف VRAM بالاتر
-
حافظه موقت (KV Cache) سنگینتر
-
احتمال Out of Memory بیشتر
📌 مثال واقعی:
در یک مدل 7B:
-
کانتکست 8K → ~۲GB VRAM
-
کانتکست 32K → ۴ تا ۶GB VRAM فقط برای کش
🔑 پیشنهاد عملی:
-
چت روزمره → 4096
-
تحلیل متن یا کد → 8192
-
اسناد حجیم → فقط در صورت نیاز بالا ببر
GPU Offloading: مهمترین اسلایدر LM Studio
این گزینه تعیین میکند:
چه تعداد از لایههای مدل روی GPU اجرا شوند
هرچه لایههای بیشتری روی GPU باشد:
-
سرعت بالاتر
-
فشار کمتر روی CPU
اگر کارت گرافیک قوی داری:
-
اسلایدر را روی Max بگذار
-
مخصوصاً RTX 3060 به بالا
اگر VRAM محدود است:
-
حدود ۱ گیگابایت فضا خالی بگذار
-
اگر سیستم کرش کرد، یک مقدار کم کن
📌 قانون طلایی:
GPU تا مرز پر شدن خوب است، پر شدن کامل = کرش
CPU Threads: اینجا اشتباه نکن!
اگر بخشی از مدل روی CPU اجرا میشود (یا کلاً CPU-only هستی):
-
تعداد Threads را برابر هستههای فیزیکی بگذار
-
نه هستههای منطقی (Hyper-Threading)
مثال:
-
CPU 8-core / 16-thread
-
مقدار مناسب → 8
بیشتر گذاشتن:
-
باعث گلوگاه
-
افزایش Latency
-
و حتی کندتر شدن میشود
Temperature، Top-P و کنترل رفتار مدل
این بخش روی «خلاقیت» مدل اثر دارد.
Temperature
-
0.1 تا 0.3 → دقیق، خشک، منطقی
-
0.7 → متعادل (پیشنهادی)
-
1.0+ → خلاق، ولی احتمال هذیان
Top-P
-
معمولاً 0.9 یا 0.95 عالی است
-
کمتر → محافظهکار
-
بیشتر → آزادتر
📌 پیشنهاد عملی:
-
برنامهنویسی → Temp: 0.2
-
مقاله و تولید محتوا → Temp: 0.7
-
ایدهپردازی → Temp: 0.9
حالا وقت بخش خفن ماجراست 😎
راهاندازی API محلی در LM Studio
یکی از قدرتمندترین قابلیتهای LM Studio این است که میتواند:
مثل ChatGPT یک سرور API محلی اجرا کند
بدون اینترنت
بدون هزینه
کاملاً خصوصی
فعالسازی Local Server
۱. وارد تب Developer شو
2. مدل را لود کن
3. روی Start Server کلیک کن
معمولاً این آدرس ساخته میشود:
http://localhost:1234
نکته مهم:
LM Studio از پروتکل OpenAI پشتیبانی میکند.
یعنی چی؟
یعنی هر ابزاری که برای ChatGPT نوشته شده، میتواند با LM Studio کار کند 😍
اتصال LM Studio به VS Code (Continue)
اگر برنامهنویس هستی، این بخش طلاست.
۱. افزونه Continue را نصب کن
۲. تنظیمات افزونه را باز کن
۳. این مدل را اضافه کن:
{
"title": "LM Studio Local",
"model": "qwen2.5-coder-7b",
"apiBase": "http://localhost:1234/v1",
"provider": "openai"
}
حالا:
-
AutoComplete
-
Chat با کد
-
Refactor
-
توضیح کد
همهچیز:
✅ آفلاین
✅ بدون ارسال کد به سرور خارجی
برای پروژههای محرمانه، این یک نعمت است.
اتصال به Python و LangChain
اگر با پایتون کار میکنی، داستان خیلی ساده است.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url=”http://localhost:1234/v1″,
api_key=”lm-studio”,
model=”qwen2.5-coder-7b”
)
print(llm.invoke(“تفاوت Q4 و Q8 را توضیح بده”).content)
با این کار میتونی:
-
چتبات بسازی
-
سیستم RAG راه بندازی
-
تحلیل داده انجام بدی
بدون پرداخت حتی یک ریال توکن.
۳ پروژه کاربردی با LM Studio
حالا که ابزار دستته، اینها پروژههای واقعیاند:
۱. پرسش و پاسخ از فایلهای محرمانه (Local RAG)
اگر:
-
قرارداد
-
پایاننامه
-
فایل مالی
داری که نباید آپلود شود:
روش:
-
تب Chat
-
بخش Chat with Documents
-
فایل PDF یا TXT را اضافه کن
نتیجه:
-
خلاصهسازی
-
پرسش و پاسخ
-
تحلیل دقیق
همهچیز آفلاین، ۱۰۰٪ امن.
۲. ویراستار حرفهای محتوا
یک System Prompt ساده:
تو یک ویراستار حرفهای هستی. متن زیر را از نظر لحن، روانی و گرامر اصلاح کن.
برخلاف ChatGPT:
-
محدودیت تعداد پیام نداری
-
محدودیت حجم متن نداری
-
ساعتها میتونی روی یک مقاله کار کنی
۳. شبیهسازی مصاحبه شغلی یا مذاکره
از مدل بخواه:
-
نقش مصاحبهکننده فنی
-
مدیر منابع انسانی
-
یا مذاکرهکننده حرفهای
را بازی کند.
اگر با TTS ترکیب شود:
-
یک محیط تمرین کاملاً خصوصی داری
-
بدون استرس
-
بدون ضبط شدن صدا 😄
خطایابی LM Studio و حل مشکلات رایج
حتی اگر بهترین سختافزار دنیا را هم داشته باشی، اجرای مدلهای محلی همیشه بیدردسر نیست. خبر خوب این است که ۹۰٪ مشکلات LM Studio تکراریاند و راهحل مشخص دارند. این بخش دقیقاً برای همین نوشته شده.
مشکل ۱: خطای Out of Memory (کمبود حافظه)
نشانهها:
-
مدل لود نمیشود
-
برنامه کرش میکند
-
پیام خطای حافظه میبینی
علت:
-
VRAM کارت گرافیک پر شده
-
یا RAM سیستم جوابگو نیست
راهحلها (به ترتیب اولویت):
-
GPU Offload را کمتر کن
-
Context Length را کاهش بده
-
نسخه سبکتر مدل (Q4 → Q3 یا Q2) دانلود کن
-
برنامههای سنگین دیگر را ببند
📌 نکته مهم:
همیشه حداقل ۱GB VRAM آزاد برای سیستمعامل باقی بگذار.
مشکل ۲: سرعت خیلی پایین (کمتر از ۲–۳ توکن در ثانیه)
علتهای رایج:
-
GPU شناسایی نشده
-
مدل روی CPU اجرا میشود
-
CPU قدیمی بدون AVX2
بررسی سریع:
-
هنگام لود مدل، آیکون GPU سبز است؟
-
در Task Manager یا Activity Monitor مصرف GPU دیده میشود؟
راهحلها:
-
درایور کارت گرافیک را آپدیت کن
-
GPU Offload را فعال کن
-
اگر CPU-only هستی، انتظار معجزه نداشته باش 😄
مشکل ۳: پاسخهای ناقص یا Incomplete JSON (در API)
این خطا معمولاً وقتی پیش میآید که:
-
مدل متن خیلی طولانی تولید میکند
-
به سقف Context برخورد میکند
راهحل:
-
Context Length را افزایش بده
-
یا خروجی را کوتاهتر بخواه
-
از مدلهایی با کانتکست بزرگتر استفاده کن (مثل Qwen)
مشکل ۴: خطاهای Metal در مک
ارورهای معروف:
-
Unable to build metal library
-
Metal device not supported
علت:
-
نسخه macOS قدیمی
-
ناسازگاری Metal با LM Studio جدید
راهحل:
-
آپدیت macOS به Ventura یا بالاتر
-
یا نصب نسخه قدیمیتر LM Studio
مشکل ۵: مدل فارسی بد جواب میدهد
واقعیت تلخ 😅
همه مدلها برای فارسی ساخته نشدهاند.
پیشنهاد:
-
Qwen 2.5
-
Llama 3.1
-
Yi
و حتماً:
-
System Prompt فارسی دقیق بنویس
-
از Temperature خیلی بالا استفاده نکن
چند ترفند حرفهای که خیلیها نمیدانند
🔹 System Prompt همهچیز را تغییر میدهد
بهجای توضیح در هر پیام، یک System Prompt قوی بنویس:
تو یک متخصص هوش مصنوعی هستی که پاسخها را دقیق، مرحلهبهمرحله و بدون حاشیه میدهد.
نتیجه؟
-
خروجی پایدارتر
-
هذیان کمتر
-
کیفیت بالاتر
🔹 یک مدل برای هر کار
همهچیز را با یک مدل انجام نده.
-
کدنویسی → DeepSeek / Qwen Coder
-
متن فارسی → Qwen
-
تحلیل منطقی → Llama
-
سرعت بالا → Mistral
🔹 Context بالا ≠ کیفیت بهتر
خیلیها فکر میکنند Context زیاد یعنی خروجی بهتر.
نه همیشه.
گاهی:
-
Context کمتر
-
Prompt دقیقتر
نتیجه بهتری میدهد.
آینده LM Studio و Local AI
ما دقیقاً وسط یک تغییر پارادایم هستیم.
از:
هوش مصنوعی بهعنوان سرویس ابری
به:
هوش مصنوعی بهعنوان ابزار شخصی
مدلهای متنباز با سرعت عجیبی در حال رشدند:
-
Llama 4
-
DeepSeek R2
-
Qwen 3
و ابزارهایی مثل LM Studio:
-
اجرای MoE
-
Speculative Decoding
-
و مدلهای چندمرحلهای
را ساده و در دسترس کردهاند.
جمعبندی نهایی
اگر بخواهم خیلی خلاصه بگویم:
LM Studio یعنی:
-
هوش مصنوعی بدون اینترنت
-
بدون هزینه اشتراک
-
بدون نگرانی امنیتی
تسلط بر LM Studio:
-
فقط یادگیری یک نرمافزار نیست
-
یک مهارت آیندهمحور است
کسی که Local AI را بلد باشد:
-
مصرفکننده صرف نیست
-
سازنده و کنترلکننده ابزار است
قدم بعدی تو چیست؟
اگر تا اینجا آمدهای:
-
LM Studio را نصب کن
-
یک مدل Q4 مناسب سیستمات دانلود کن
-
API محلی را فعال کن
-
حداقل یک پروژه واقعی با آن بساز
بعد از آن، دیگر نگاهت به ChatGPT مثل قبل نخواهد بود 😉
